UD11: APLICACIONS WEB HÍBRIDES¶

INTRODUCCIÓ¶
En la indústria del desenvolupament de programari és habitual reutilitzar funcionalitats i serveis desenvolupats per tercers, així com la utilització de fonts públiques de dades que puguem incorporar a la nostra aplicació o sistema.
En aquesta unitat revisarem diferents possibilitats amb les quals podem enriquir les nostres aplicacions web amb dades i funcionalitats de tercers: d'una banda, farem una introducció al web scraping com a forma de recollir determinades dades disponibles en format web; d'altra banda, revisarem diferents serveis de diverses plataformes que ens permetran automatitzar operacions com l'enviament de correus electrònics, gestió de fitxers estàtics, passarel·les de pagament, etc.
AVALUACIÓ¶
El present document, juntament amb el seu corresponent butlletí d'activitats (publicat addicionalment), cobreix els següents criteris d'avaluació:
| RESULTATS D'APRENENTATGE | CRITERIS D'AVALUACIÓ |
|---|---|
| RA4. Desenvolupa aplicacions Web embegudes en llenguatges de marques analitzant i incorporant funcionalitats segons especificacions. | f) S'han utilitzat eines i entorns per facilitar la programació, prova i depuració del codi. |
| RA9. Desenvolupa aplicacions Web híbrides seleccionant i utilitzant llibreries de codi i repositoris heterogenis d'informació. | a) S'han reconegut els avantatges que proporciona la reutilització de codi i l'aprofitament d'informació ja existent. b) S'han identificat tecnologies i frameworks aplicables en la creació d'aplicacions web híbrides. c) S'ha creat una aplicació web que recupere i procese repositoris d'informació ja existents. d) S'han creat repositoris específics a partir d'informació existent en magatzems d'informació. e) S'han utilitzat llibreries de codi i frameworks per incorporar funcionalitats específiques a una aplicació web. |
WEB SCRAPING¶
Internet representa una gran i valuosa font de dades en nombroses àrees d'interès. Hi ha diferents possibilitats per recollir dades a través d'Internet:
- Jocs de dades ja existents:
- Públics: hi ha nombrosos conjunts de dades ja preparats per entrenar diferents algoritmes d'Intel·ligència Artificial. Pots trobar alguns d'aquests exemples en aquest enllaç.
- Compra de jocs de dades: en nombroses plataformes és possible comprar jocs de dades sobre diverses temàtiques: consum, medi ambient, política... Un exemple el pots trobar en aquest enllaç.
- Dades corporatives: són les dades transaccionals o agregades, generades per l'activitat privada d'una empresa o organització.
- Creació de jocs de dades:
- Generació de dades: mitjançant la creació d'enquestes, o la utilització de serveis com AmazonTurk, que permeten contractar personal per a tasques com etiquetatge de dades i classificació.
- Recollida de dades existents: mitjançant serveis API REST.
En la unitat anterior vam veure com recuperar dades de diverses API REST, dissenyades per a tal efecte, però, què passa si hi ha llocs web que no proporcionen un servei web similar?
Per a aquests casos es pot utilitzar Web Scraping, que és una tècnica consistent a extraure dades del codi HTML dels llocs web. Abans d'aplicar aquesta tècnica a un lloc web, cal tenir en compte determinats factors:
- Legals
- S'incompleix alguna normativa nacional/regional?
- S'incompleixen els "Termes i condicions" del lloc web?
- S'està accedint a llocs no autoritzats?
- És legal l'ús que es donarà a les dades?
- Ètics
- Robots.txt: és un fitxer amb informació perquè els motors de cerca no indexen determinades pàgines d'un lloc web. Per accedir a aquest fitxer, s'afegeix "/robots.txt" al final d'un determinat domini, de la forma "domini.com/robots.txt". Ací es detallen aspectes com si es permet/denega accés total o parcial, freqüència de consultes (crawl-delay), el sitemap (per facilitar la navegació pel lloc), etc. Per a més informació, consulta aquest enllaç. No respectar les normes establertes en aquest fitxer pot comportar conseqüències legals.
En cas de dubtes sobre si es pot aplicar aquesta tècnica a un determinat lloc web, el millor consell és contactar amb l'empresa/organització i preguntar.
Tipus de llocs web¶
Hi ha diferents casuístiques que ens podem trobar quan intentem aplicar Web Scraping en un lloc web, depenent del paradigma en què estiga basat el lloc web en qüestió:
- HTML pre-renderitzat o llocs web estàtics: són llocs web el codi HTML dels quals s'envia des del servidor (backend), ja siga perquè es tracta d'un lloc web estàtic, perquè s'utilitzen frameworks amb sistemes de plantilles (Laravel, CodeIgniter, Django...) que embeguen codi de servidor en HTML, o també perquè s'utilitza la tècnica de SSR en aplicacions web reactives (Vue, React, Angular...). En aquest cas l'HTML s'obté en fer una petició HTTP, i es poden utilitzar llibreries com BeautifulSoup4 o Scrapy.
- Single Page Application (SPA): consisteix en un fitxer HTML simple amb codi JavaScript associat. Durant la navegació, el navegador web executa el codi JavaScript i modifica dinàmicament el codi HTML per alliberar el servidor d'aquesta tasca. Les dades es descarreguen mitjançant peticions HTTP a serveis REST que resideixen en el servidor, actualitzant-se només la part de l'HTML que es necessita, sense originar un refresc de tota la pàgina web. En fer una petició HTTP, el que s'obté és l'HTML simple i no les dades que es visualitzen en pantalla (ja que és el codi JavaScript, en el costat client, qui modifica l'HTML, després de fer-se la petició HTTP). En aquest cas hi ha dues aproximacions per a Web Scraping:
- Utilitzar una eina com Selenium, per simular un navegador web que accedeix al lloc web, i així poder executar el codi JavaScript que genere el codi HTML. Selenium és realment un entorn de proves per a aplicacions web, encara que el seu ús ha derivat també cap al Web Scraping. A més de per a SPAs, Selenium també es pot utilitzar per als llocs web de la tipologia anterior.
- Inspeccionar les peticions HTTP que es realitzen al backend per descobrir els endpoints, i així poder fer peticions HTTP directament a aquests endpoints i recuperar les dades en format JSON (generalment).
A més d'aquestes consideracions, caldrà establir si es requereix algun tipus d'autenticació en fer la petició HTTP.
Exemples de Web Scraping¶
A continuació desenvoluparem dos exemples de Web Scraping, un amb BeautifulSoup4, i un altre amb Selenium. Per a això, prèviament haurem d'instal·lar en el nostre entorn virtual els paquets corresponents:
pip install beautifulsoup4
pip install selenium
Fake jobs - BeautifulSoup4¶
En aquest exemple extraurem determinades dades d'una web amb ofertes de treball falses. La URL de la qual extraurem aquestes dades és:
https://realpython.github.io/fake-jobs/
I les dades de cada oferta són:
- Títol
- Companyia
- Ubicació
Una vegada tenim clares les dades que necessitem extraure, així com la URL on trobar aquestes dades, hauríem de plantejar-nos si s'incompleix algun tipus de norma tant legal com ètica (segons les consideracions esmentades en l'apartat introductori). En tractar-se d'un lloc de proves específicament dissenyat per a practicar Web Scraping, no tenim cap impediment per continuar amb les proves.
Com a segon pas a realitzar (previ a la programació del script o bot), és essencial analitzar l'estructura del lloc web del qual volem descarregar les dades. Per a això, hem d'inspeccionar el codi HTML amb el navegador que estiguem utilitzant. En el cas de Google Chrome, polsem el botó dret del ratolí sobre l'element a inspeccionar, i polsem sobre "Inspecciona", després del qual ens apareixeran les eines de desenvolupador, sobre la pestanya "Elements", i apuntant directament a l'element sobre el qual havíem polsat el botó dret del ratolí:
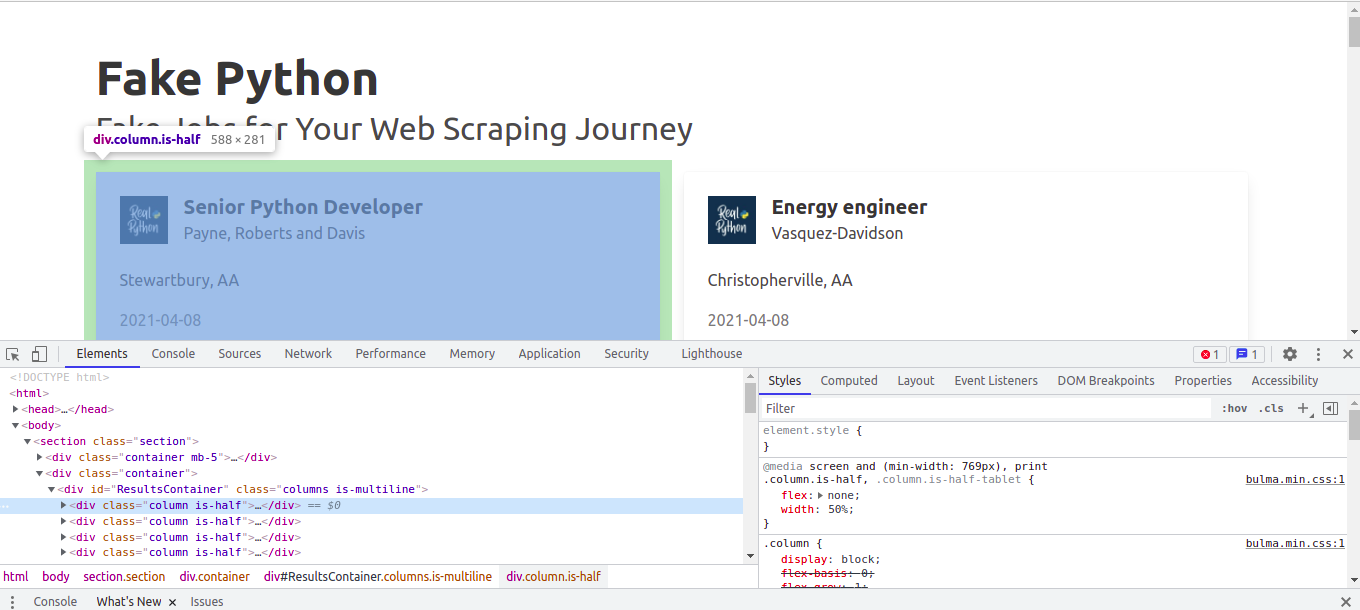
Tornarem a aquesta estructura més endavant, però ara anem a introduir les primeres instruccions de codi:
import requests
from bs4 import BeautifulSoup
URL = "https://realpython.github.io/fake-jobs/"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
El segon paràmetre "html.parser" indica el tipus de parser que s'utilitzarà. Un parser servirà per poder distingir entre els diferents elements d'un document basat en llenguatge de marques (HTML en aquest cas) per poder navegar per ells posteriorment. En el cas de BeautifulSoup, podem trobar tres tipus:
- html.parser: és el parser que ve per defecte instal·lat en la llibreria estàndard de Python.
- lxml: combina característiques d'XML i es caracteritza per la seua rapidesa.
- html5lib: es caracteritza per interpretar l'HTML de la mateixa manera que un navegador web.
En general, utilitzaríem lxml quan necessitàrem rapidesa. A més, per a versions de Python iguals o anteriors a la 3.2.2, es recomana usar lxml o html5lib. Per saber més sobre les diferències d'aquests parsers, es pot consultar aquest enllaç.
Trobar elements per ID¶
Després d'inspeccionar el codi HTML segons s'ha descrit anteriorment, veiem que les ofertes de treball estan contingudes en elements div amb classe "card", al seu torn contingut en un div amb classes "column is-half". Tots aquests elements div estan al seu torn continguts en un element div amb l'atribut id amb valor "ResultsContainer". Per tant, aquest és el primer element a partir del qual començar la cerca:
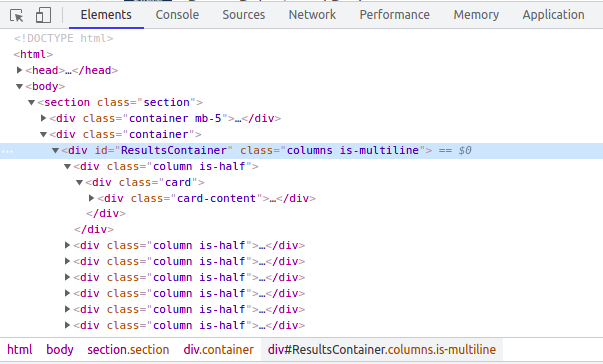
La instrucció per fer això serà:
results = soup.find(id="ResultsContainer")
Si volguérem veure de forma "amigable" l'HTML obtingut, podem utilitzar la següent instrucció:
print(results.prettify())
Trobar elements per etiqueta i classe¶
Una vegada hem acotat la part del document que conté les dades que ens interessen, anem a localitzar exactament on es troben aquestes dades:
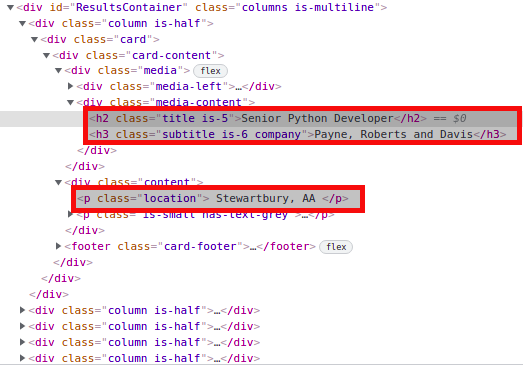
Per tant, es pot apreciar que les dades que necessitem es troben dins d'un element div amb classe "card-content". Per poder recuperar tots els elements amb aquesta classe, utilitzem la següent instrucció:
job_elements = results.find_all("div", class_="card-content")
Amb el mètode find_all obtindrem un iterable que podrem recórrer amb un bucle:
for job_element in job_elements:
title_element = job_element.find("h2", class_="title")
company_element = job_element.find("h3", class_="company")
location_element = job_element.find("p", class_="location")
print(title_element)
print(company_element)
print(location_element)
print()
NOTA: Si haguérem utilitzat el mètode find en lloc de find_all, només hauríem recuperat el primer dels elements de l'arbre amb les característiques especificades.
Per cada job_element (que també és un objecte de BeautifulSoup) dins de job_elements, buscarem diferents elements (h2, h3 i p) amb les seues corresponents classes (title, company i location). A continuació imprimim els seus valors, i una línia en blanc al final de cada bloc.
L'eixida del bucle té la següent aparença:
<h2 class="title is-5">Senior Python Developer</h2>
<h3 class="subtitle is-6 company">Payne, Roberts and Davis</h3>
<p class="location">Stewartbury, AA</p>
Per arrodonir aquesta primera prova, anem a extraure el text dels elements anteriors mitjançant la funció get_text(), i el resultat el concatenarem amb la funció strip() per extraure els possibles espais en blanc. Així el script quedaria de la següent manera:
import requests
from bs4 import BeautifulSoup
URL = "https://realpython.github.io/fake-jobs/"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
results = soup.find(id="ResultsContainer")
job_elements = results.find_all("div", class_="card-content")
for job_element in job_elements:
title_element = job_element.find("h2", class_="title")
company_element = job_element.find("h3", class_="company")
location_element = job_element.find("p", class_="location")
print(title_element.get_text().strip())
print(company_element.get_text().strip())
print(location_element.get_text().strip())
print()
Per a llançar aquest script, el guardem primer en un fitxer amb extensió .py (per exemple fake_jobs_scraping.py), seguidament activem l'entorn virtual des del terminal, i l'executem de la forma:
(venv) usuari: python /"ruta fins al fitxer"/fake_jobs_scraping.py
(venv) usuari: python fake_jobs_scraping.py
Dades de criptomonedes - Selenium¶
Com s'ha comentat anteriorment, Selenium s'utilitza, en l'entorn de Web Scraping, quan s'intenta descarregar dades d'una aplicació web i cal realitzar determinades accions abans que es carregue la pàgina web (per exemple, polsar sobre un botó).
En aquest apartat utilitzarem Selenium per extraure dades sobre criptomonedes, d'aquest lloc web.
Anàlisi del lloc web¶
La primera consideració a tindre en compte és l'estructura de la pàgina web. Hem d'estudiar-la prèviament per poder programar les accions que Selenium ha de dur a terme.
Per poder realitzar aquestes accions, haurem d'utilitzar les funcionalitats de Selenium que ens permetran polsar sobre els elements de la pàgina web, i per poder fer això haurem d'esperar que els elements estiguen disponibles en el DOM. Amb aquest fi realitzarem les següents importacions al nostre script, que ens permetran esperar fins que els elements del DOM permeten realitzar determinades accions sobre ells:
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from time import sleep
Configuració del scraper¶
En primer lloc, la instal·lació del paquet selenium en l'entorn virtual (com vam veure al principi d'aquest apartat) no serà suficient per poder manejar el navegador: haurem d'instal·lar el driver corresponent perquè, a través d'ell, es puga manejar el navegador mitjançant codi Python.
Aquest driver ha de ser instal·lat en el host on tenim instal·lat l'entorn virtual. Per a això instal·lem el següent paquet en l'entorn virtual:
https://pypi.org/project/chromedriver-autoinstaller/
En segon lloc, farem les importacions corresponents i configurarem el webdriver perquè el navegador s'execute en segon pla i no es mostre per pantalla. A més, guardarem la URL de la qual volem obtindre les dades:
from selenium import webdriver
from bs4 import BeautifulSoup
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from time import sleep
import chromedriver_autoinstaller
URL = 'https://coinmarketcap.com/en/'
chromedriver_autoinstaller.install()
chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument("--headless")
chrome_options.add_argument("--window-size=1920,1200")
browser = webdriver.Chrome(options=chrome_options)
browser.get(URL)
Copia totes aquestes instruccions a un nou fitxer anomenat coinmarketcap_scraper.py.
Una possible llista de totes les opcions que es poden configurar per al navegador es llisten en aquest enllaç.
NOTA: S'ha comentat l'opció "headless", que amaga l'execució del navegador per poder comprovar les operacions que realitza i poder entendre qualsevol error que succeïsca en l'execució dels passos. Una vegada es depure el script, podem descomentar aquesta línia perquè el navegador no es mostre. Mentrestant, mostrarem el navegador amb una mida 1920 x 1200, així es mostrarà en una mida prou gran perquè no es contraguen els menús (per ser una pàgina adaptativa, o responsive), la qual cosa ens canviaria l'estructura del DOM, i que hauríem de tindre també en consideració en el nostre script.
Acceptació de cookies¶
El primer que anem a programar és l'acceptació del missatge de cookies. Encara que en aquest lloc web no entorpeix la navegació, ho farem a mode il·lustratiu. Quan entrem per primera vegada al lloc web (o en mode incògnit), es mostra el missatge d'acceptació de cookies. Si examinem el botó de "Accept All Cookies" podem analitzar les seues característiques:
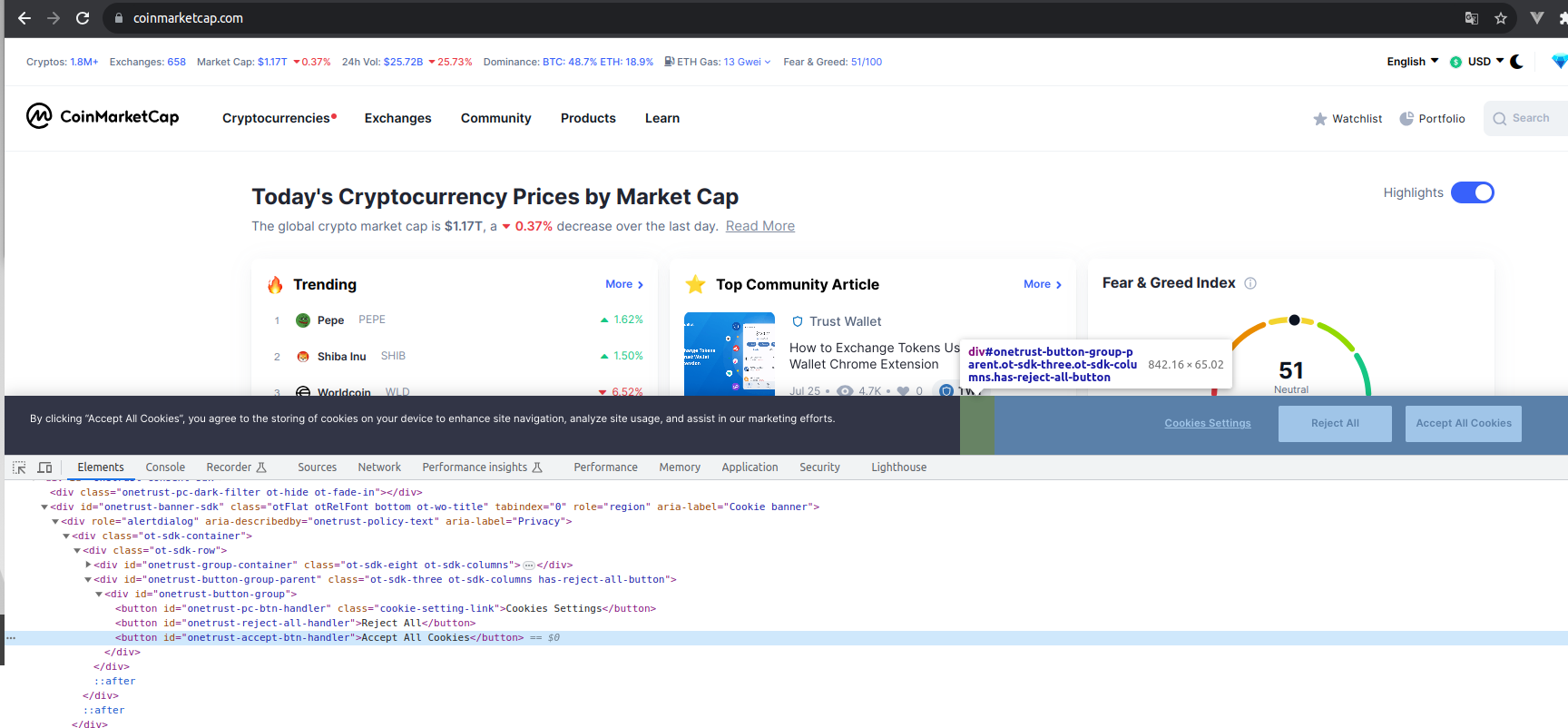
Veiem que aquest element button té un id amb valor "onetrust-accept-btn-handler". Això ens servirà per poder identificar-lo, amb les següents instruccions:
accept_cookies_button = WebDriverWait(browser, 10).until(EC.element_to_be_clickable((By.ID, "onetrust-accept-btn-handler")))
Amb aquesta instrucció, li diem al navegador que espere 10 segons com a màxim fins que l'element amb l'id especificat estiga en condicions de poder ser polsat. Per simular el polsador sobre el botó, afegim la següent instrucció:
accept_cookies_button.click()
Afegeix aquestes dues instruccions al fitxer coinmarketcap_scraper.py, i l'executem amb l'entorn virtual activat:

Després d'executar aquest comandament veuràs el navegador Chromium apareix i s'executen les accions programades, i es tanca el navegador. Si vols apreciar millor les accions que es realitzen, afegeix la següent línia al final del script, perquè el navegador tarde 10 segons més a tancar-se i apreciar millor el que ha passat:
sleep(10)
Amagar Highlights¶
Pretenem amagar el bloc de Highlights que es mostra en entrar a la pàgina web. Això s'aconsegueix polsant sobre el switch ressaltat en la següent captura:
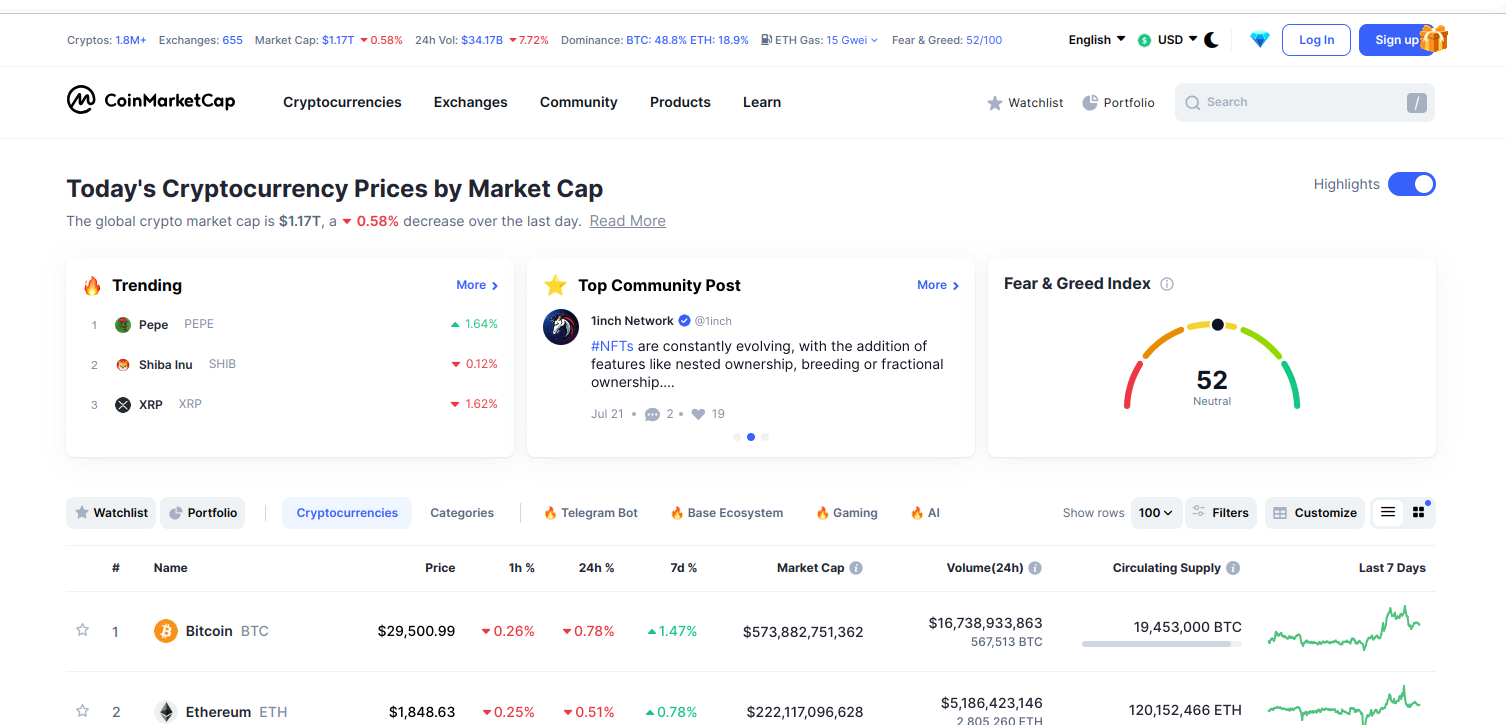
Per saber l'element del DOM amb el qual hem d'interactuar, hem d'inspeccionar-lo i analitzar les seues característiques, per poder diferenciar-lo de la resta dels elements:
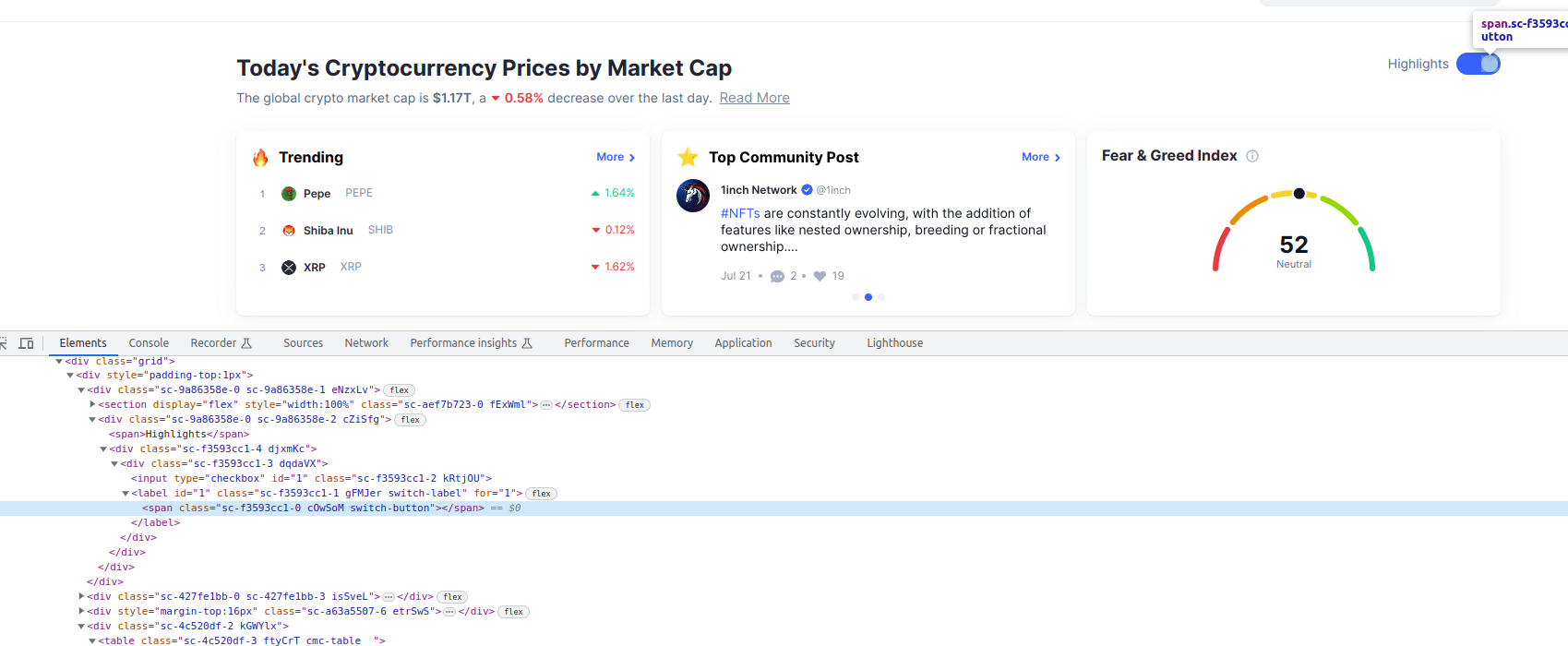
Veiem que es tracta d'un element span amb tres classes associades, una d'elles anomenada "switch_button". Si inspeccionem tot el codi HTML, veiem que no existeix cap altre element que tinga associada aquesta classe, per tant el nom de la classe és un candidat perfecte per identificar aquest botó de forma única.
Anem a afegir les següents instruccions en el fitxer, abans de la instrucció sleep (que serà l'última):
switch_button = WebDriverWait(browser, 5).until(EC.element_to_be_clickable((By.CLASS_NAME, "switch-button")))
switch_button.click()
Executem de nou el script i observem les accions.
Fins aquest punt, hem utilitzat dos atributs de la classe By, per localitzar elements dins de la pàgina: ID i CLASS_NAME.
Però hi ha més atributs i estratègies. Anem a aprofundir un poc més mitjançant el següent enllaç per conéixer més possibilitats de cerca.
Canvi d'idioma¶
La següent acció que volem automatitzar és el canvi d'idioma. Per a això, hem de polsar en el desplegable de cerca d'idioma, introduir les primeres lletres (o el nom complet) de l'idioma que volem seleccionar i, quan aparega en el desplegable, polsar sobre ell:
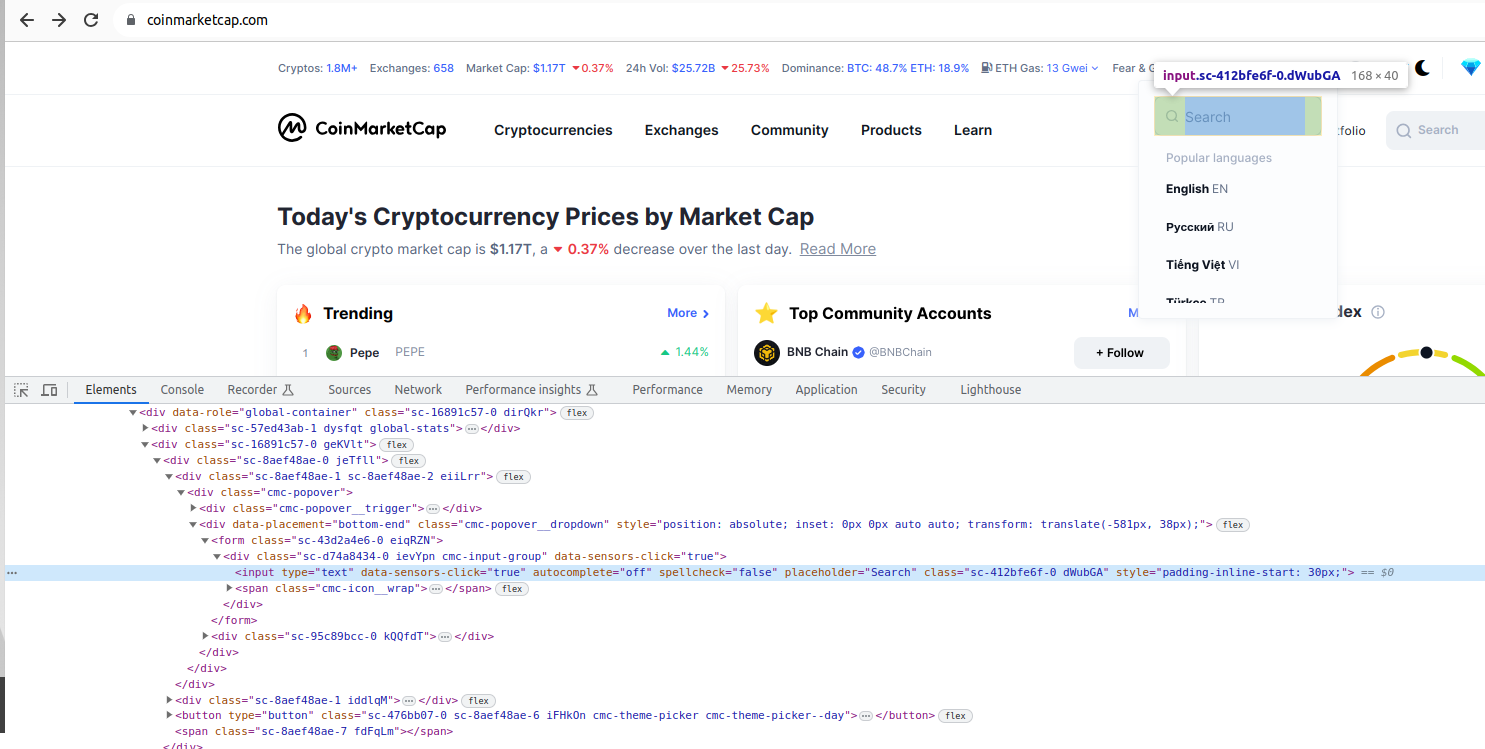
Hem trobat l'element input en el qual volem introduir el nom de l'idioma al qual volem canviar. Analitzant el comportament de forma manual, veiem que aquest desplegable només es mostra si polsem sobre l'opció de canvi d'idioma (que pren per defecte l'idioma del teu navegador).
Per tant, la primera opció serà la de trobar l'opció de canvi d'idioma en la barra de navegació superior, i polsar sobre aquesta opció perquè es desplegue la cerca d'idioma.
Anem a examinar l'element del qual estem parlant:
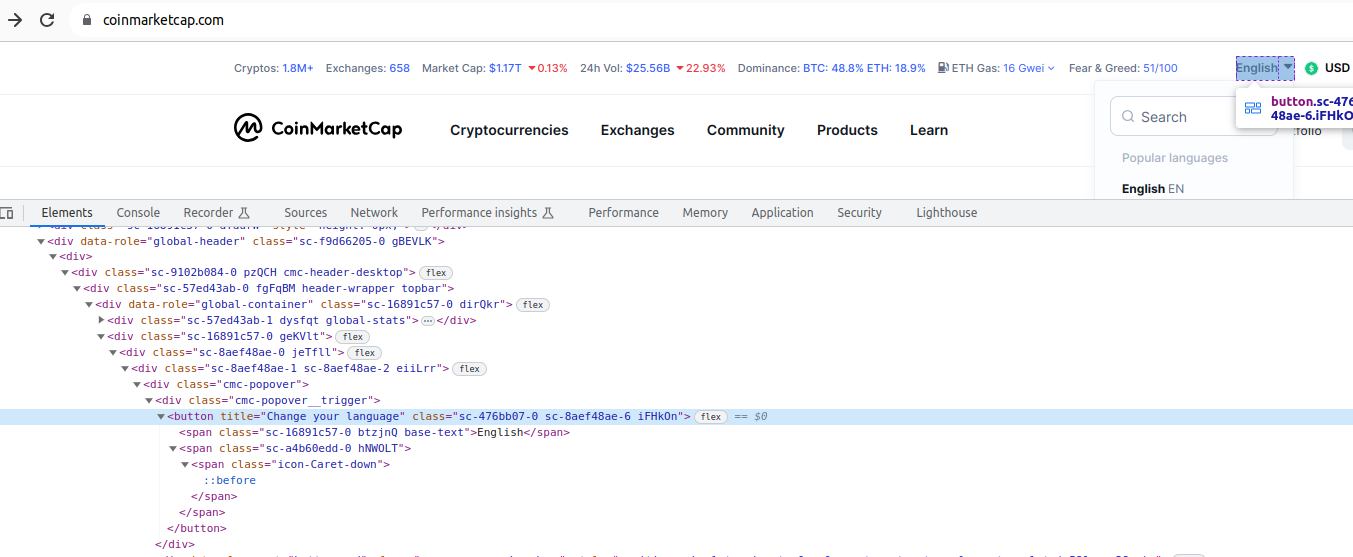
Comprovem que es tracta d'un element button, amb un títol (en l'idioma per defecte del navegador) i unes determinades classes que no són identificatives. Donat això, anem a ancorar la cerca a partir de l'element per damunt del botó, el div amb classe "cmc-popover__trigger", i a partir d'ací triem l'element button immediatament inferior. Però, com fem això si fins al moment només sabem buscar per ID o classe? Ho farem amb una expressió XPath. Si estàs familiaritzat amb XPath t'és més fàcil entendre l'exemple, si no ho estàs, ací tens un resum.
Es tracta de, mitjançant una expressió XPath, trobar l'element button en qüestió a través de l'arbre del document HTML.
Hi ha diverses possibilitats:
- Partir de l'element arrel html, i anar descendint un a un en els elements de l'arbre, amb alguna cosa semblant a:
/html/body/div/div/div/div/div/div/div/div/div/div/div/div/div/div/form/div/input
Això és una forma poc robusta de desenvolupar el nostre script, ja que si els desenvolupadors canvien algun detall d'aquesta estructura, es pot invalidar el nostre script.
- Com no volem fer alguna cosa tan tediosa com l'anterior, utilitzarem rutes relatives de XPath.
Aquestes són les instruccions que ens permetran trobar el botó de canvi d'idioma, i polsar sobre ell, amb l'expressió XPath ressaltada:
language_button = WebDriverWait(browser, 5).until(EC.element_to_be_clickable((By.XPATH, "//div[@class='cmc-popover__trigger']/button")))
language_button.click()
Ara hem de controlar la llista d'idiomes que es desplega en polsar sobre el botó anterior. Examinem de nou l'HTML:
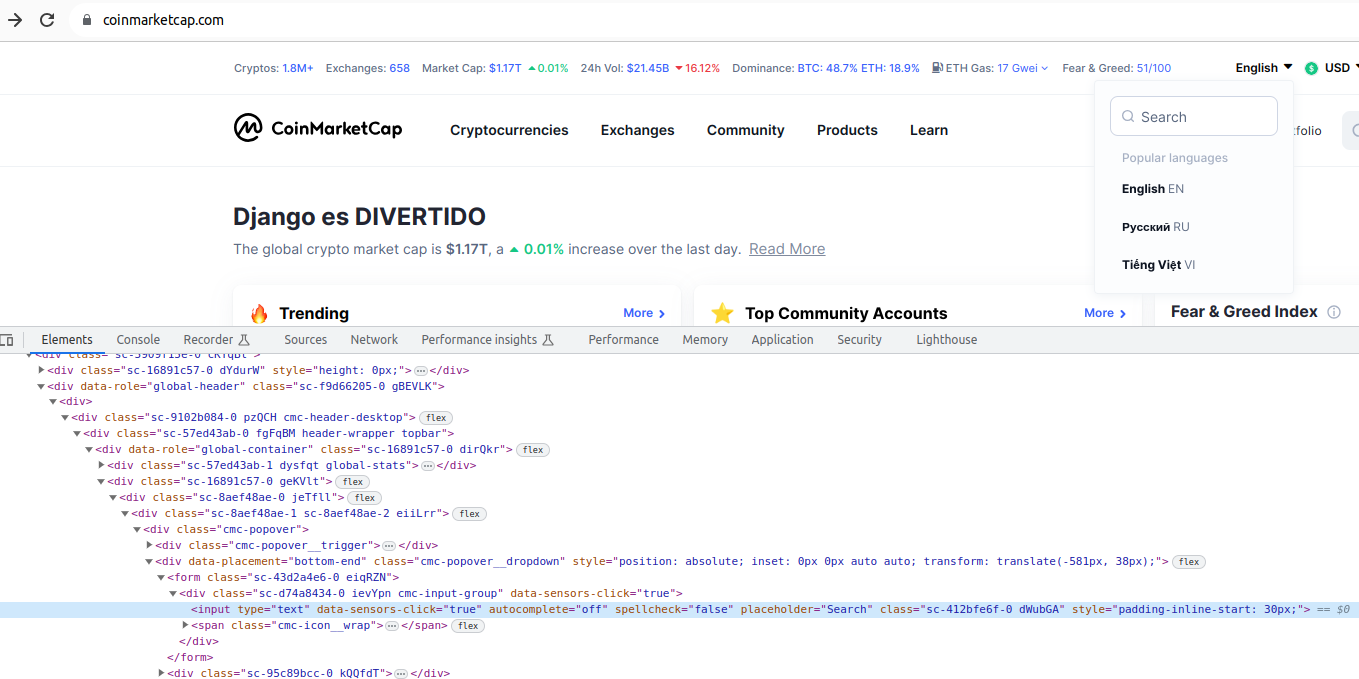
Veiem que l'element que ens permet buscar un idioma particular és un input. Quan el despleguem, és l'únic input que existeix en la barra de navegació superior, amb la qual cosa podem prendre el div amb classe "topbar" i buscar dins d'ell un input, d'aquesta manera:
topbar = browser.find_element(By.CLASS_NAME, 'topbar')
language_input = topbar.find_element(By.XPATH, ".//input")
topbar = browser.find_element(By.CLASS_NAME, 'topbar')
language_input = WebDriverWait(topbar, 5).until(EC.presence_of_element_located((By.XPATH, ".//input")))
Ara només ens queda fer una cerca de l'idioma, i per a això utilitzem el mètode send_keys amb l'element input, de la forma (triem l'alemany com a idioma):
language_input.send_keys("Deutsch")
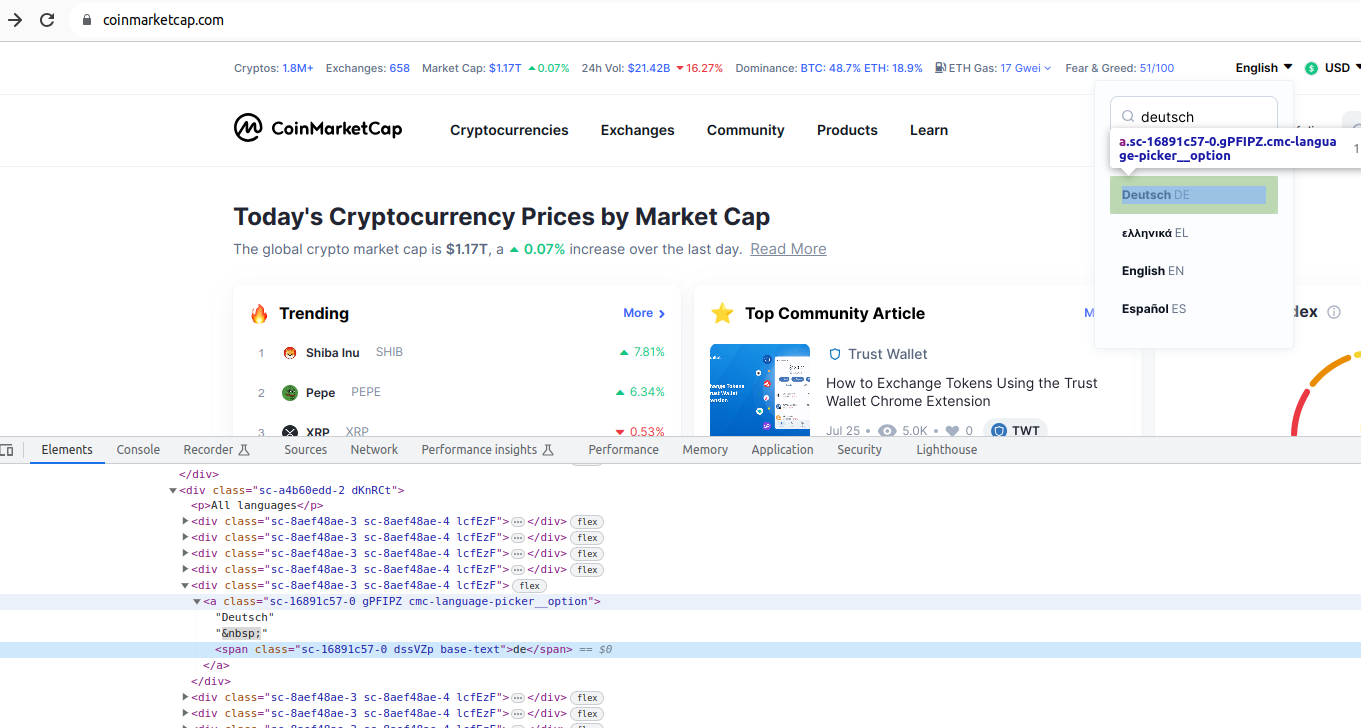
Per tant, només ens queda polsar sobre l'enllaç que conté el text "Deutsch". Per a això, utilitzem un altre criteri de cerca de la classe By, anomenat PARTIAL_LINK_TEXT (establim una espera, per a més seguretat), i el codi de canvi d'idioma resultant és el següent:
language_button = WebDriverWait(browser, 5).until(EC.element_to_be_clickable((By.XPATH, "//div[@class='cmc-popover__trigger']/button")))
language_button.click()
topbar = browser.find_element(By.CLASS_NAME, 'topbar')
language_input = WebDriverWait(topbar, 5).until(EC.presence_of_element_located((By.XPATH, ".//input")))
language_input.send_keys("Deutsch")
deutsch_option = WebDriverWait(browser, 5).until(EC.element_to_be_clickable((By.PARTIAL_LINK_TEXT, 'Deutsch')))
deutsch_option.click()
Provem el script resultant en classe i comprovem que es canvia l'idioma correctament.
Descàrrega de les 30 que més guanyen¶
Ja hem dut a terme operacions bàsiques de navegació del lloc web. Ara anem a començar a descarregar dades, en concret les 30 criptomonedes que més estan guanyant en aquests moments.
Es pot apreciar que les dades que necessitem no es troben en la pàgina de benvinguda:
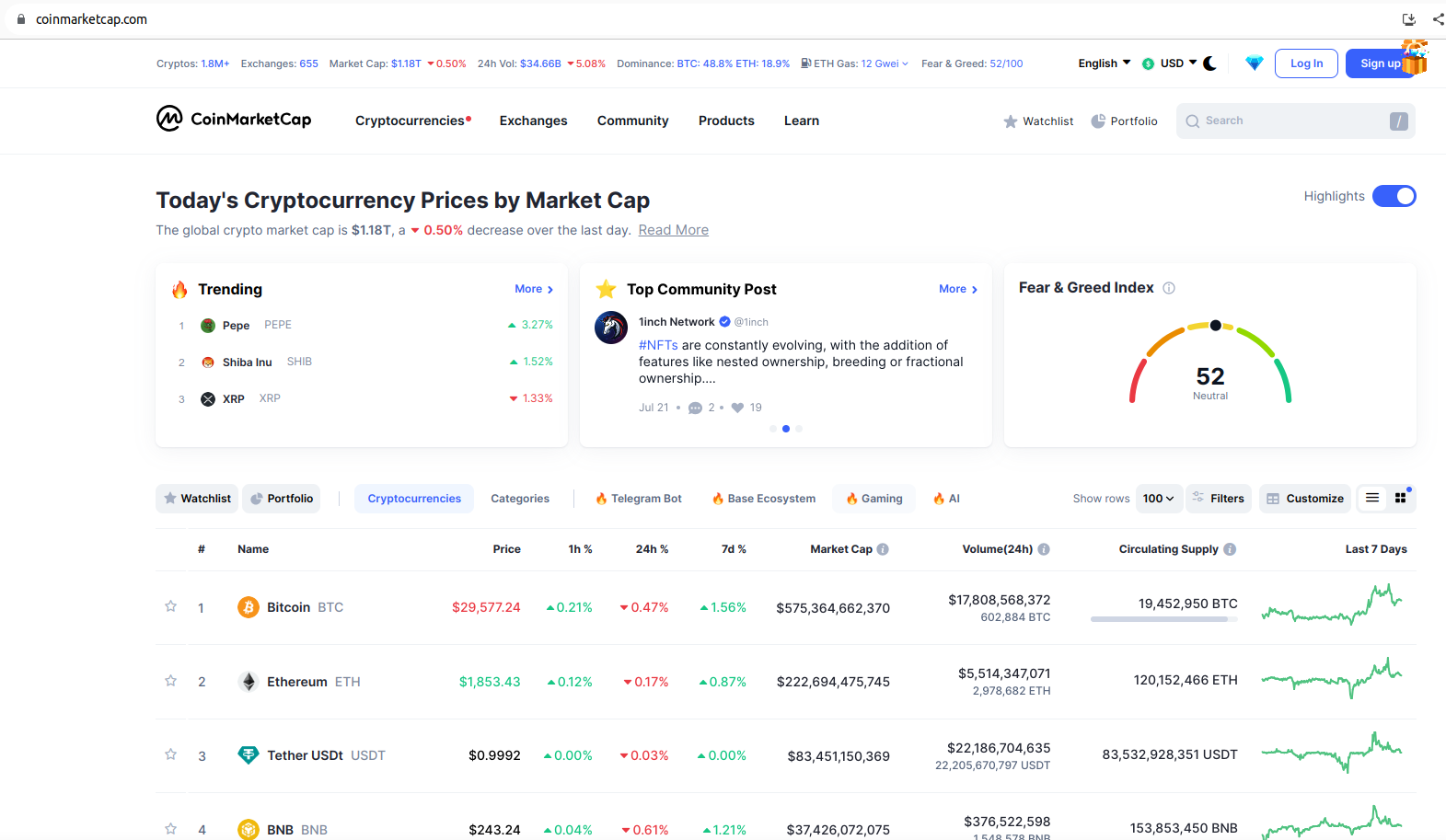
És necessari polsar sobre l'opció de menú Cryptocurrencies i després sobre Gainers & Losers:
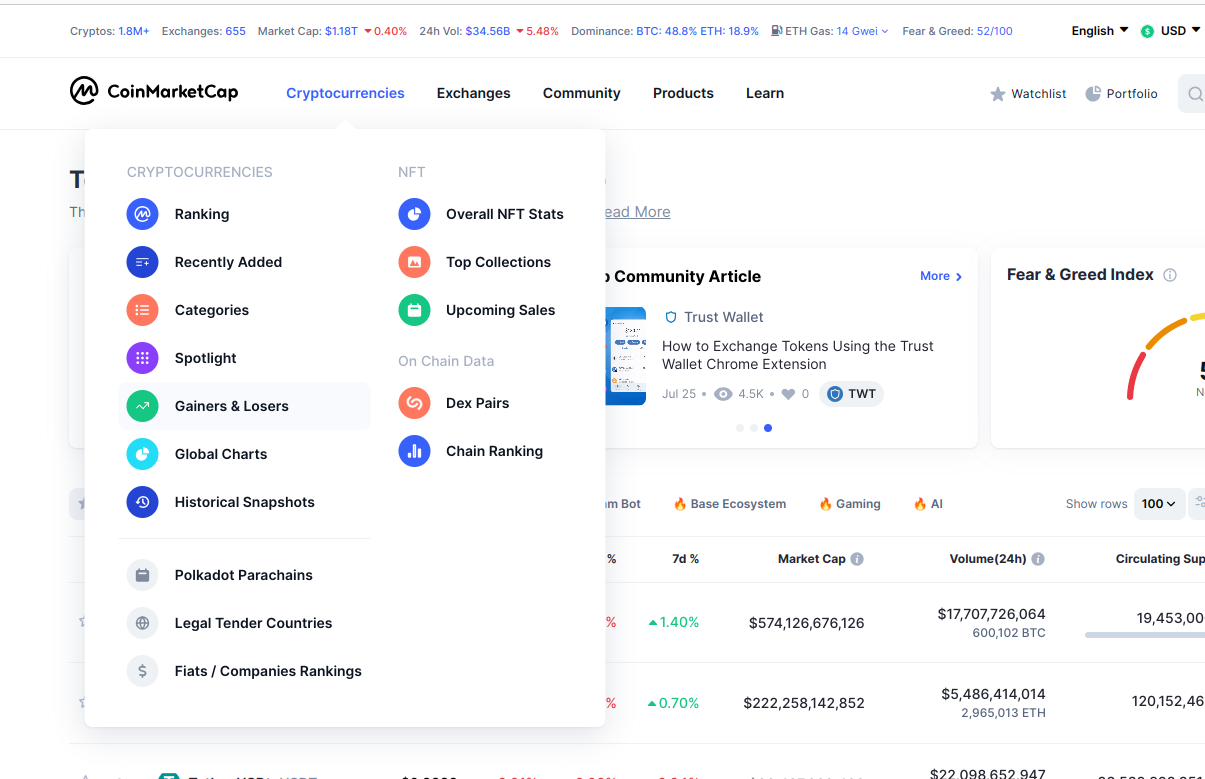
A continuació es mostren 2 blocs: un amb les 30 primeres criptomonedes que més guanyen, i 30 amb les que més perden:
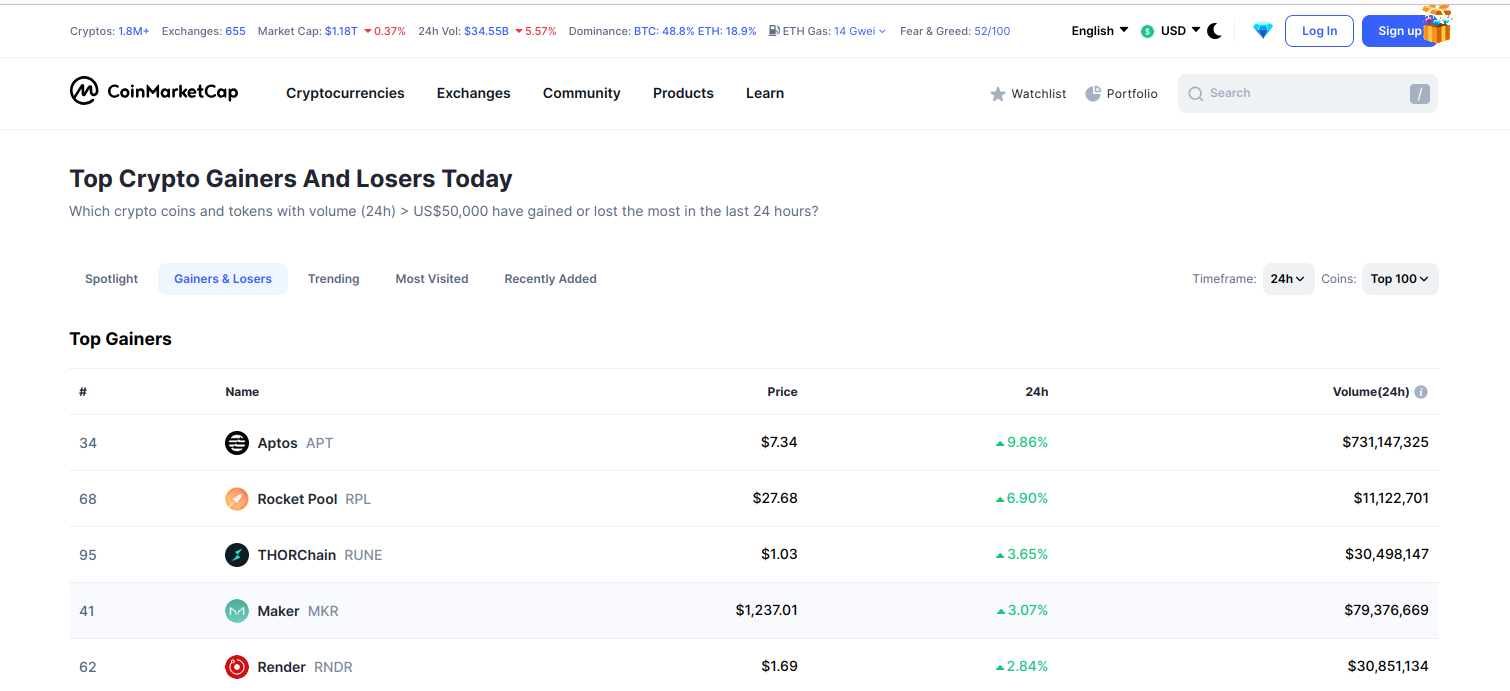
A continuació haurem de polsar sobre l'opció de menú corresponent. Sabrem quina és aquesta opció inspeccionant l'HTML de la pàgina:
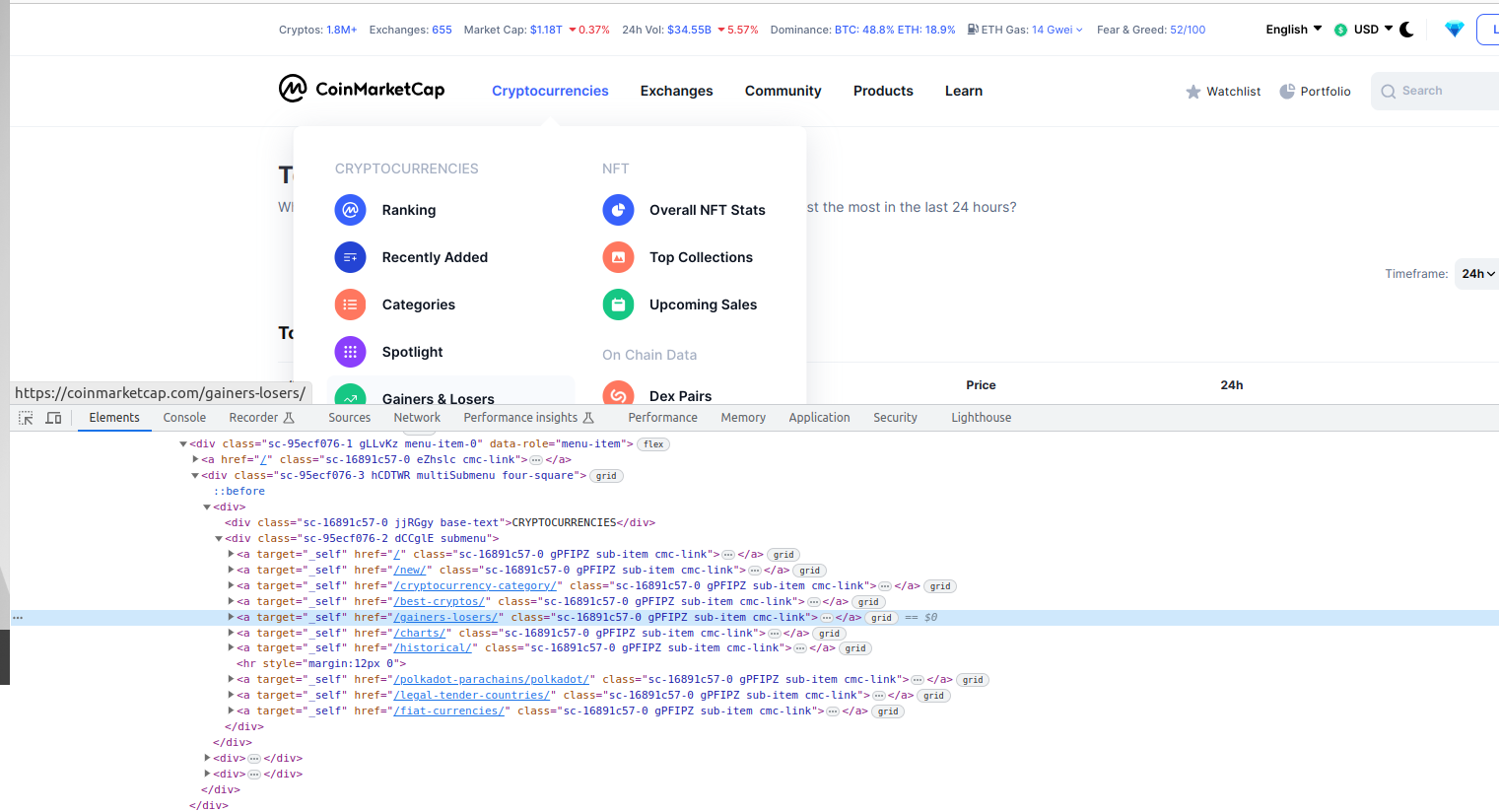
Veiem que es tracta d'un enllaç el atribut href del qual conté el valor /gainers-losers/, pel que el més fàcil serà navegar directament a aquesta URL:
url_gainers_losers = 'https://coinmarketcap.com/gainers-losers/'
browser.get(url_gainers_losers)
Si examinem el codi d'aquesta pàgina web del lloc web, veurem que hi ha dos blocs diferenciats, un per als que més guanyen, i un altre per als que més perden, en forma de taules:
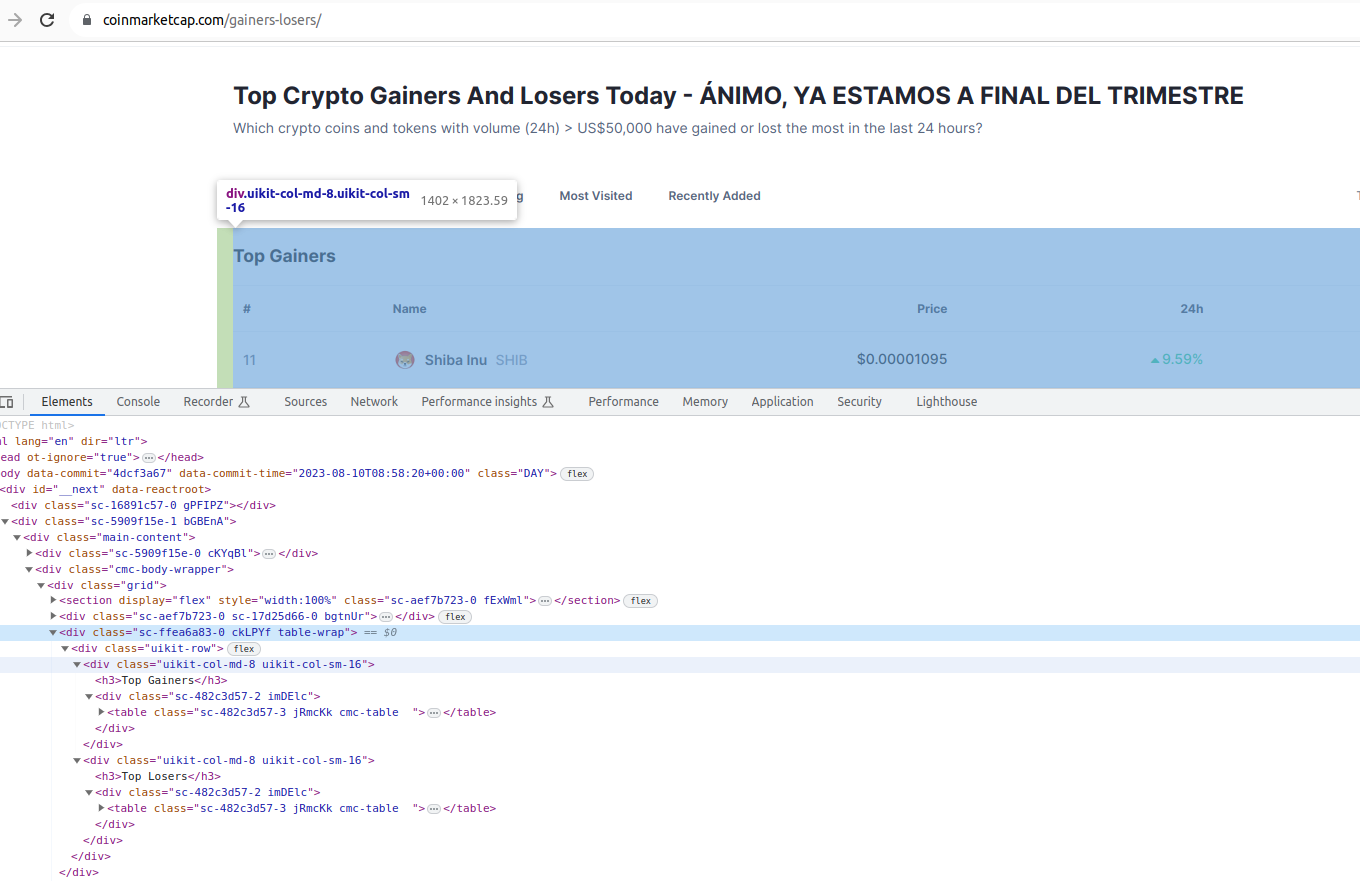
Podem apreciar que no hi ha forma de diferenciar els dos blocs, per algun ID o classe particular, amb la qual cosa ens basarem en prendre la primera de les dues taules que trobem.
Això ho podem fer en dos passos, per a més seguretat. Primer esperem que l'element que embolica les dues taules (amb classe "table-wrap") estiga present en el document, utilitzant un wait. A continuació, simplement utilitzem la funció find_elements dins de l'element embolcallant (no necessitem wait perquè l'element embolcallant ja està present), i prenem el primer dels elements que ens retorna aquesta funció utilitzant la notació de claudàtors [0]:
table_wrap = WebDriverWait(browser, 5).until(EC.presence_of_element_located((By.CLASS_NAME, "table-wrap")))
tables = table_wrap.find_elements(By.XPATH, ".//table")
table_gainers = tables[0]
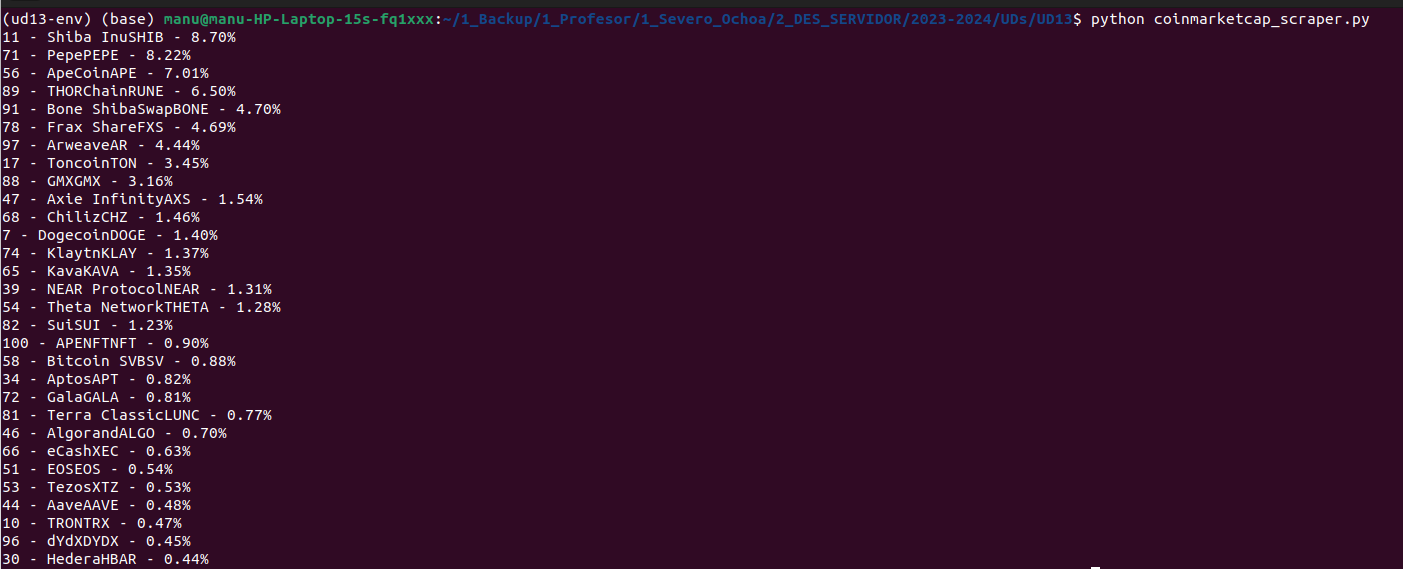
Finalment, accedim a les files de la taula amb un bucle, i imprimim alguns camps de cada fila en forma de text:
rows = table_gainers.find_elements(By.XPATH, ".//tbody/tr")
for row in rows:
cells = row.find_elements(By.XPATH, ".//td")
row_text = (cells[0].text + ' - ' + cells[1].text + ' - ' + cells[3].text).replace("\n", "")
print(row_text)
L'eixida del script ha de mostrar un resultat semblant al següent (depenent del moment en què s'execute):
Conversió a dataframe de pandas¶
Volem convertir les dades de la taula de les criptomonedes que més guanyen, de l'apartat anterior, a un dataframe de pandas.
Pandas és una llibreria molt útil en l'àmbit de Big Data, Intel·ligència artificial i intel·ligència de negocis. Serveix com a eina per a l'anàlisi i manipulació de dades. L'objecte mitjançant el qual pandas realitza operacions s'anomena dataframe, consistent en una representació tabular de la informació (a manera de taula o full de càlcul).
Per poder utilitzar pandas amb les dades que hem extret necessitem fer prèviament una sèrie d'instal·lacions. Primer instal·lem pandas i els parsers lxml i html5 en el nostre entorn virtual, si no els tenim ja:
pip install pandas
pip install lxml
pip install html5lib
Anem a convertir l'element de selenium emmagatzemat en la variable table_gainers a un dataframe de pandas, convertint-lo primer a un objecte de BeautifulSoup com a pas intermedi, amb les següents línies (podem comentar el bucle de l'apartat anterior):
table_gainers_bs = BeautifulSoup(table_gainers.get_attribute('outerHTML'), 'html.parser')
dataframe = pd.read_html(str(table_gainers_bs))[0]
print(dataframe)
I el resultat és el següent:
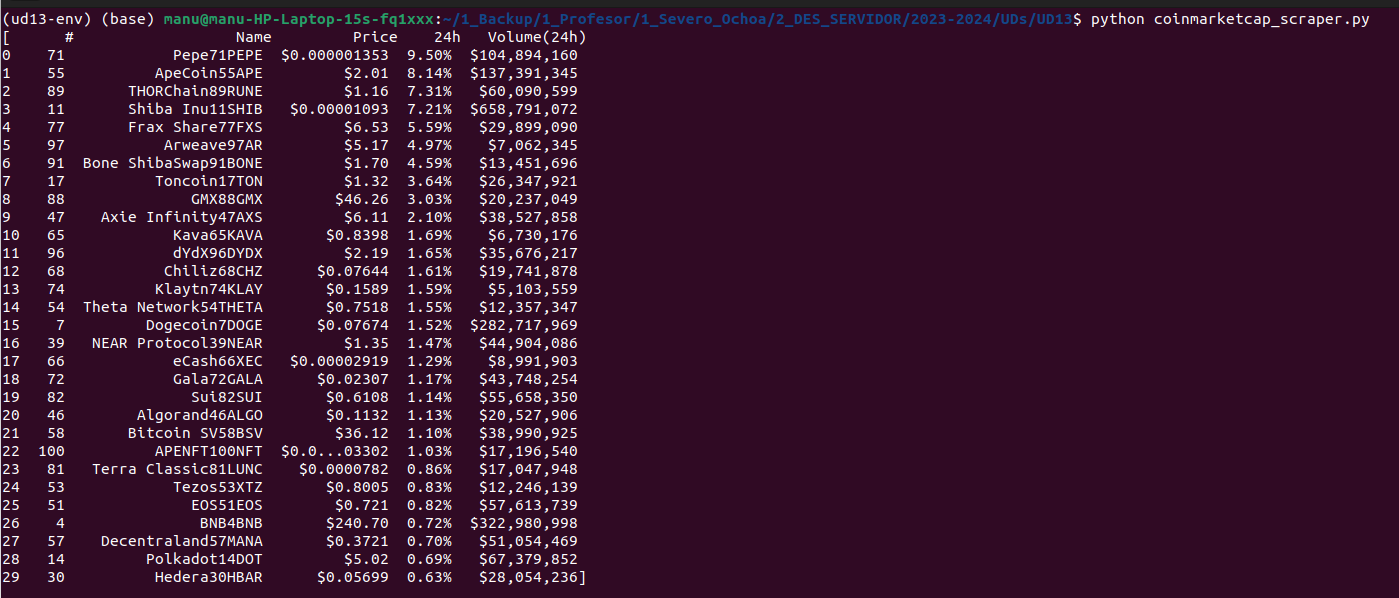
Mitjançant el dataframe de pandas podrem operar molt millor amb aquestes dades i podrem realitzar determinades operacions de forma més ràpida i eficient. Ací tens una breu introducció. Durant la resta d'aquest apartat anem a realitzar unes senzilles manipulacions al dataset creat.
En primer lloc, veiem que en imprimir el dataset, els resultats no semblen ordenats segons un sentit lògic. El que realment ens agradaria seria ordenar-los de forma descendent pel percentatge de guanys en les últimes 24 hores. Això es fa fàcilment mitjançant la següent instrucció:
dataframe = dataframe.sort_values(by=["24h"], ascending=False)
Imprimim per consola la nova versió del dataframe, i en executar el script obtenim aquest resultat:
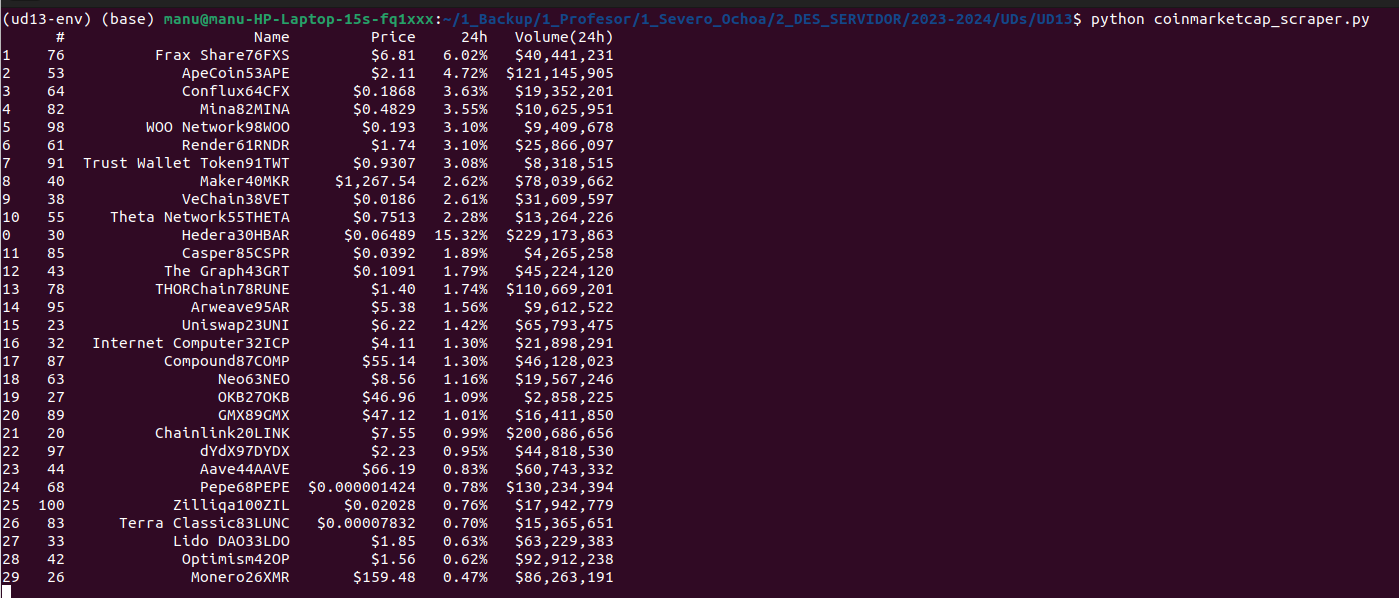
Veiem que, efectivament, s'han ordenat les files del dataframe, però no exactament com voldríem. Resulta que les dades de la columna "24h" representen un text, i pandas ha ordenat les dades com a text, no com una fracció decimal.
Per tant, necessitem convertir la columna "24h" a un número decimal, i hem d'eliminar el signe percentual al final. Això ho aconseguirem, per exemple, amb els següents dos passos: guardem els valors de la columna "24h", transformats ja a un número decimal; a continuació, inserim aquests valors processats com una nova columna, en tercer lloc (índex 2):
column_24h = dataframe["24h"].str.rstrip("%").astype('float')
dataframe.insert(loc = 2, column = "24h(%)", value = column_24h)
Estem creant una nova columna, anomenada "24h(%)", de tipus decimal. Podem esborrar també la columna "24h" de la forma, perquè ja no la necessitem:
dataframe = dataframe.drop("columns=["24h"]")
I, finalment, ordenar-ho tot per la nova columna. Podem concatenar l'esborrat de la columna amb l'ordenació de la nova, quedant:
column_24h = dataframe["24h"].str.rstrip("%").astype('float')
dataframe.insert(loc = 2, column = "24h(%)", value = column_24h)
dataframe = dataframe.drop(columns=["24h"]).sort_values(by=["24h(%)"], ascending=False)
print(dataframe)
El resultat serà el següent:
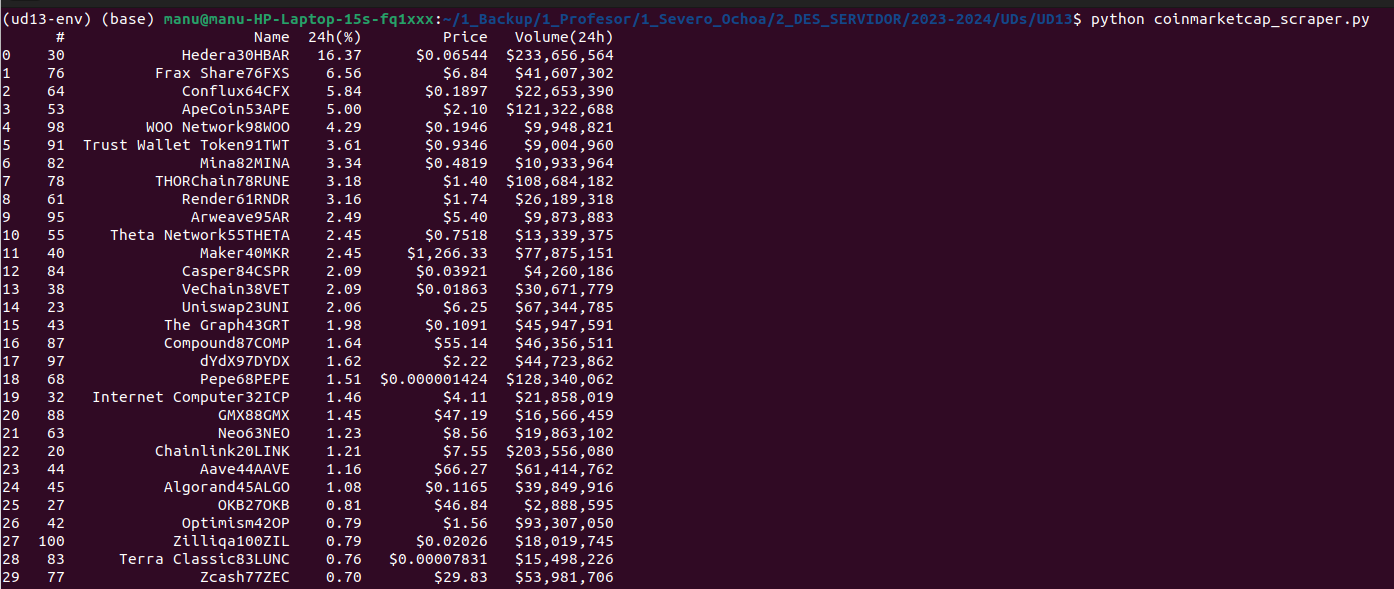
Què més podríem fer? Per exemple, podríem prendre el primer dels registres, mitjançant el mètode head:
print(dataframe.head(1))

Existeix una altra llibreria anomenada numpy, molt utilitzada conjuntament amb pandas, que dona suport a la creació de vectors i matrius multidimensionals, i una col·lecció de funcions matemàtiques.
Aquesta àrea és prou extensa com per tractar-la en un curs d'especialització de FP, com és el del Curs d'especialització d'Intel·ligència Artificial i Big Data.
Consideracions addicionals¶
Evidentment, hi ha més al voltant del Web Scraping del que s'ha detallat fins ara. A continuació es presenten més recursos i qüestions perquè amplie la teua visió sobre aquesta àrea.
Cheat sheet¶
En aquest enllaç es resumeixen més tipus de selectors (etiqueta, classe, id, atribut, CSS...), navegació entre ancestres/descendents, en BeautifulSoup.
Execució en diferents fils¶
En el cas que necessitem descarregar dades de diferents URLs (com puga ser el cas de dades paginades en un lloc web), pot ser rellevant el multiprocés en termes de velocitat.
Per a tal fi, és possible utilitzar el mòdul multiprocessing per agilitzar els processos de Web Scraping des de diferents URLs. A continuació es proporcionen dos enllaços on poder consultar diferents exemples:
How to speed up your python web scraper by using multiprocessing
Speed up web scraping using Multiprocessing in Python
Introducció de retards¶
Les peticions HTTP que es realitzen a un servidor web sobrecarreguen els recursos del lloc web, amb la qual cosa és convenient introduir mecanismes que eviten un possible col·lapse. Per a això, normalment se sol introduir retards entre les peticions HTTP al servidor.
Una primera aproximació podria ser la següent:
import time
for term in ["web scraping", "web crawling", "scrape this site"]:
r = requests.get("http://exemple.com/search", params=dict(query=term ))
time.sleep(5) # espera 5 segons
En aquest cas, es realitzaran 3 peticions HTTP, esperant 5 segons entre cadascuna d'elles.
Una altra aproximació que s'adapta als temps de resposta del servidor seria la següent:
import time
for term in ["scraping", "crawling", "scrape this web"]:
t0 = time.time()
r = requests.get("http://exemple.com/search", params=dict(query=term))
response_delay = time.time() - t0
time.sleep(10*response_delay)
En aquest cas mesurem el temps de resposta des que enviem la petició HTTP fins que es rep la resposta, i introduïm un retard 10 vegades major a eixe temps de resposta.
Emmagatzematge de les dades¶
Les dades obtingudes mitjançant Web Scraping poden ser emmagatzemades de multitud de formes per a un processat posterior. En aquesta secció es presenta l'exportació a format CSV i també l'emmagatzematge en una base de dades SQLite.
Exportar a CSV¶
Un possible bloc de codi per escriure files en un fitxer CSV podria ser el següent:
import csv
# ...
with open("ruta_al_fitxer/output.csv", "w") as f:
writer = csv.writer(f)
# elements = [
# ["Producte #1", "$10", "http://exemple.com/product-1"],
# ["Producte #2", "$25", "http://exemple.com/product-2"],
# ...
# ]
for element in elements:
writer.writerow(element)
Una altra possibilitat és guardar les files com a diccionaris de Python. Això ho aconseguirem amb la classe DictWriter, que farà correspondre cada columna del fitxer CSV amb el nom de propietat en la llista de diccionaris:
import csv
# ...
noms_camps = ["Nom del producte", "Preu", "URL de detall"]
with open("ruta_al_fitxer/output.csv", "w") as f:
writer = csv.DictWriter(f, noms_camps)
# elements = [
# {
# "Nom del producte": "Producte #1",
# "Preu": "$10",
# "URL de detall": "http://exemple.com/product-1"
# },
# ...
# ]
# Escriu una fila de capçalera
writer.writerow({x: x for x in noms_camps})
for fila in elements:
writer.writerow(fila)
Emmagatzemar en SQLite¶
Per al cas d'emmagatzematge en una base de dades SQLite, una proposta de codi és la següent:
import sqlite3
conn = sqlite3.connect("ruta_al_fitxer/output.sqlite")
cur = conn.cursor()
...
for item in collected_items:
cur.execute("INSERT INTO scraped_data (title, price, url) values (?, ?, ?)",
(item["title"], item["price"], item["url"])
)
INTEGRACIÓ AMB APIS DE TERCERS¶
Cada dia sorgeixen nous serveis web i llibreries que ens aporten funcionalitats interessants per a les nostres aplicacions web. La classificació es pot fer extensa, donat l'elevat nombre de possibilitats. A continuació s'esbossen alguns exemples:
- Geolocalització: Google Maps, OpenStreetMap, OpenLayers, LeafLet (llibreria JS)
- Enviament de correus electrònics: Mailgun, Mailchimp
- Intel·ligència artificial: Azure cognitive services, serveis d'IA d'AWS
- Passarel·les de pagament: Paypal, Stripe
- Serveis en el núvol: AWS, DigitalOcean, Linode
Com utilitzar cadascun d'aquests serveis depén de cada un dels proveïdors. Normalment es disposa d'abundant documentació, amb diferents possibilitats (mitjançant endpoints, SDK...).
El millor és provar un exemple, i per a això utilitzarem un bot de Telegram com una de les activitats d'aquesta unitat.